
在H.266视频编码标准中引入了名为依赖量化Dependent Quantization的新技术。虽然DQ技术以网格编码量化TCQ技术为基础,但是由标准文本所规定的重建过程实际并没有用到网格结构(仅在编码过程用到),因而在H.266里面的TCQ叫做DQ。
一般来说,视频编码器的量化过程会将变换之后的变换系数(如果有的话)映射为量化索引(量化系数),然后通过熵编码将他们写进码流。而解码器反量化过程会将量化索引(量化系数)反映射得到重建量化索引,作为反变换的输入。DQ属于量化模块中的一个工具,也包括量化过程和反量化过程,负责实现这样的功能。下面就来介绍一下DQ是如何工作的。
01 解码(器)角度
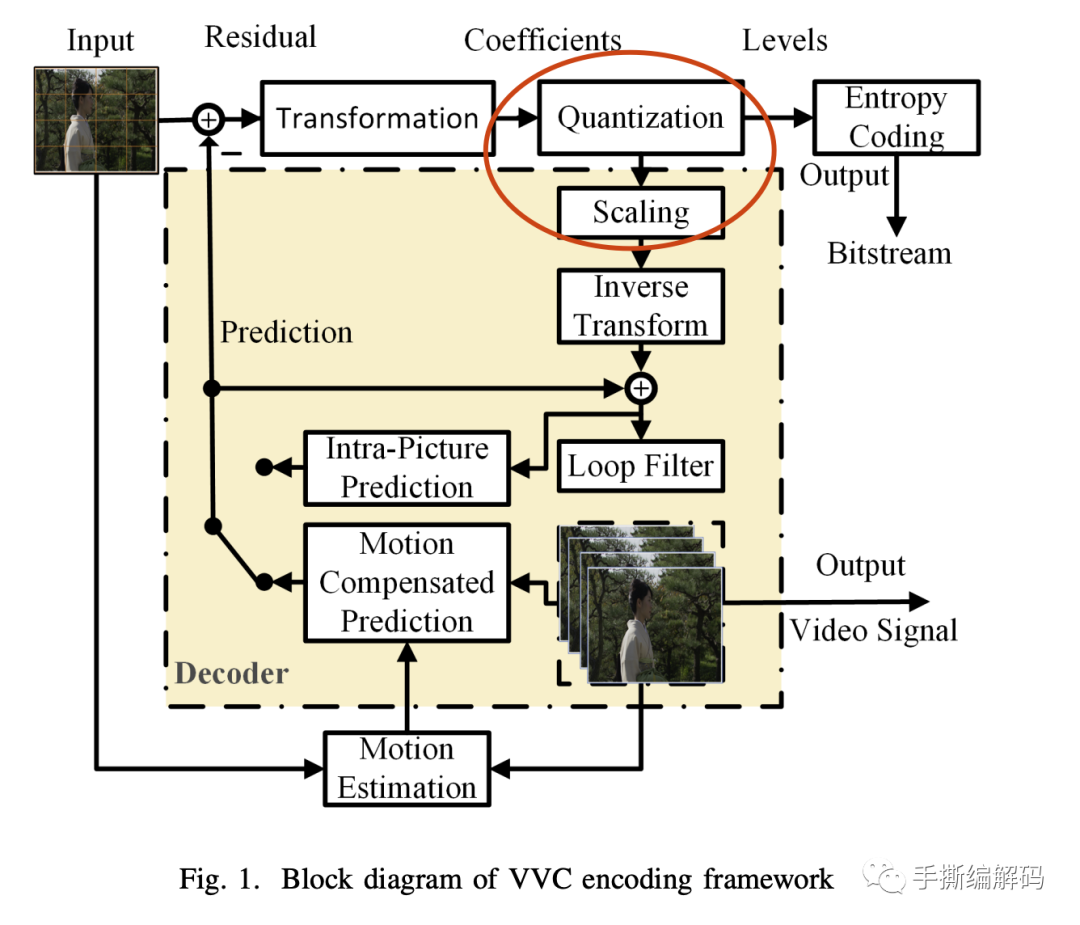
在DQ下,变换块里的反量化重建值(也叫重建变换系数),将会依赖重建顺序下的前一个量化索引,而非DQ的普通反量化过程是不需要依赖前一个量化索引的。为此,DQ技术定义并使用了两个不同的标量量化器Q0和Q1,分别对应两种不同的重建level。并定义了它们之间的转换方式和规则。这两个量化器和普通的标量量化器原理类似,每个量化器的重建levels等于量化步长的整数倍。其中Q0量化器是量化步长偶数倍,而Q1量化器是量化步长的奇数倍。如下图所示。
上图横轴下方表示的是重建levels,显然,它们的值等于量化索引乘以量化步长。
为了搞清楚标量量化器的量化索引qk,量化的输出levels和量化步长之间的关系,下面将回顾一下标量量化器的基础知识。

如上图所示,视频编码器的标量量化过程是用变换系数除以量化步长,而量化器量化得到的结果就是量化索引,也叫levels。
即quantization indexes = levels
相应的,标量量化器的反量化过程就是用量化步长乘以量化索引得到重建变换系数,也叫重建levels。上图圆圈上的数字表示量化索引,圆圈下的值则是重建levels。
考虑视频编码器支持量化矩阵,并且变换块里不同位置的变换系数可以有不同的量化步长,将反量化过程带入量化参数QP以后,可以写作: 上式等号右边的前两项即为量化步长。
上式等号右边的前两项即为量化步长。
我们知道,视频编码标准里规定了反量化过程。对上式H.266的标量量化的反量化过程考虑了整数运算和移位操作后有如下的公式:
其中m,p,b都是scaling缩放参数,W和H则是变换块的宽度和高度。
普通标量量化要得到重建变换系数,只要将变换块写进码流里面的coeff解码以后,乘以量化步长即可。而和普通的标量量化不同的是,使用DQ的量化器要得到一个块的重建变换系数,必须按照预先定义好的顺序进行重建,而这个顺序会用块内系数的索引k来表示。且重建顺序和使用TCQ来编码量化索引qk的顺序相同。
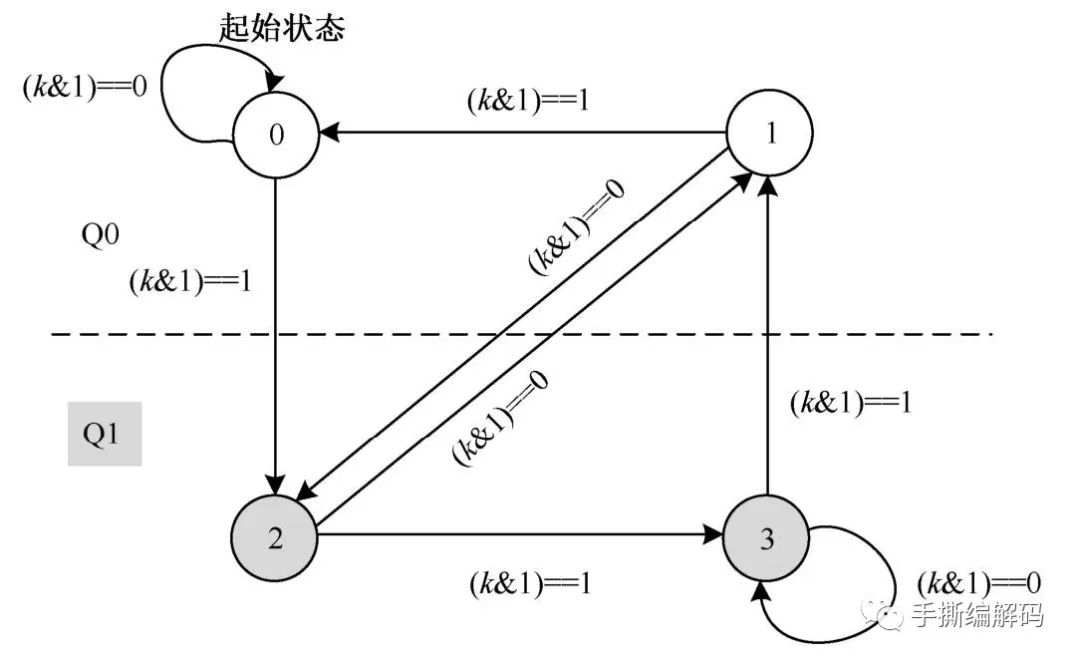
给定重建顺序下,在Q0和Q1两个量化器之间的切换过程可以通过一个状态机来确定。当前系数的状态sk唯一决定使用哪个量化器,下一个系数的状态,是由当前状态sk和当前量化索引qk的奇偶性决定。H.266为了降低编码复杂度,采用的状态机只有4个状态。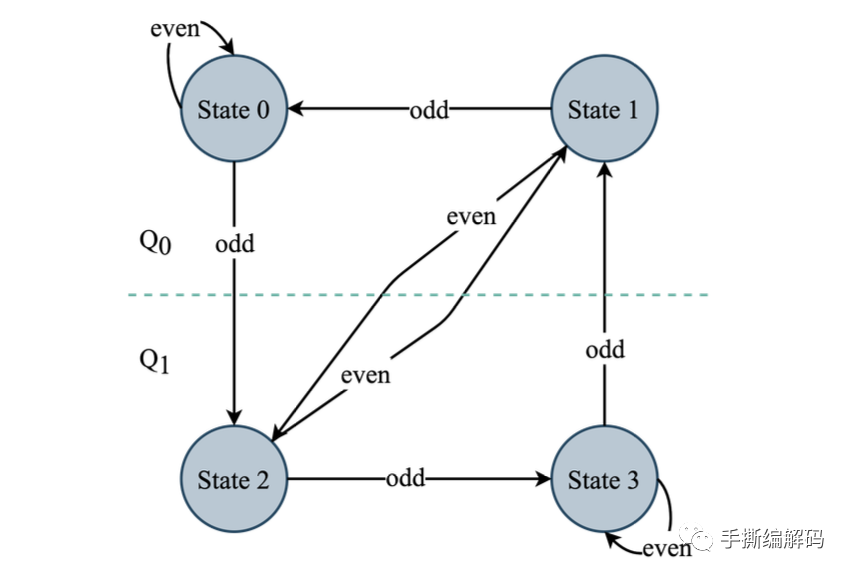
如上图所示,当状态sk为0或1时,使用标量量化器Q0。当状态sk为2或3时,则使用标量量化器Q1。箭头方向指出的下一个状态由当前状态和当前量化索引qk的奇偶性确定。
状态转换和量化器的选择如下表所示: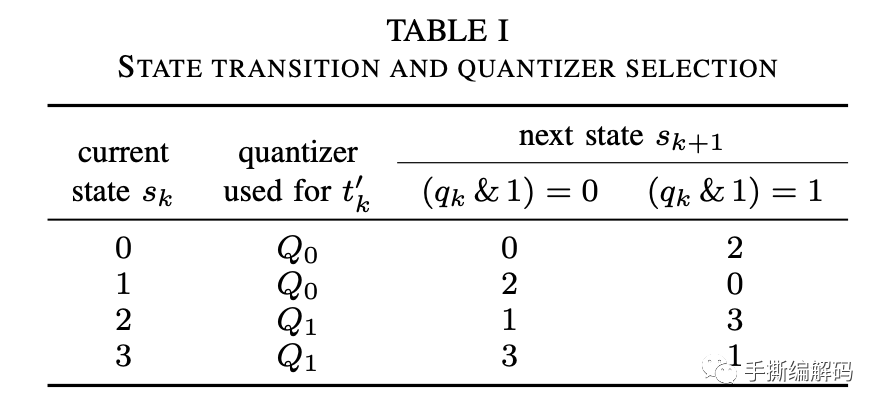
初始状态s0总是等于0。
对有N个量化系数的变换块的解码,如果确定了每个系数的当前状态sk,就可以确定量化器(步长),再根据量化索引qk就可以得到重建变换系数值,即反量化输出结果。DQ工具重建或者解码变换系数的算法过程如下图所示:
其中stateTransTable对应上面TABLE I的4×2表格,sgn()表示符号函数。系数状态的更新过程还可以表示为: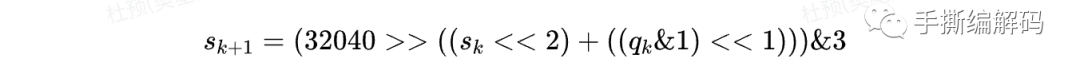 对应的H.266标准文本里的算法描述是:
对应的H.266标准文本里的算法描述是:

当然,跟普通标量量化器一样,DQ最终也是使用整数运算和移位操作计算反量化系数,如下所示:
只不过scaling参数b,p,m做了一些修改。
编码侧使用的标量量化器(Q0或Q1)在码流中没有显式地写进去。所以解码重建时是用在重建顺序中位于当前变换系数之前的量化索引的奇偶性来确定当前变换系数的量化器。
02 编码器角度
从编码的角度,需要决策出最佳的量化索引序列,等价于找到具有最小RD Cost的网格路径。所选的量化索引和标量量化器Q0或Q1之间的依赖关系,可以用网格结构来描述。使用率失真代价来标记网格节点之间的所有连接,并寻找出网格中代价最小的路径,便可以确定出最小率失真代价时的最佳量化索引。编码端在量化时实际会用一个5状态网格结构。H.266里面用来确定最佳量化索引的基本网格结构如下图: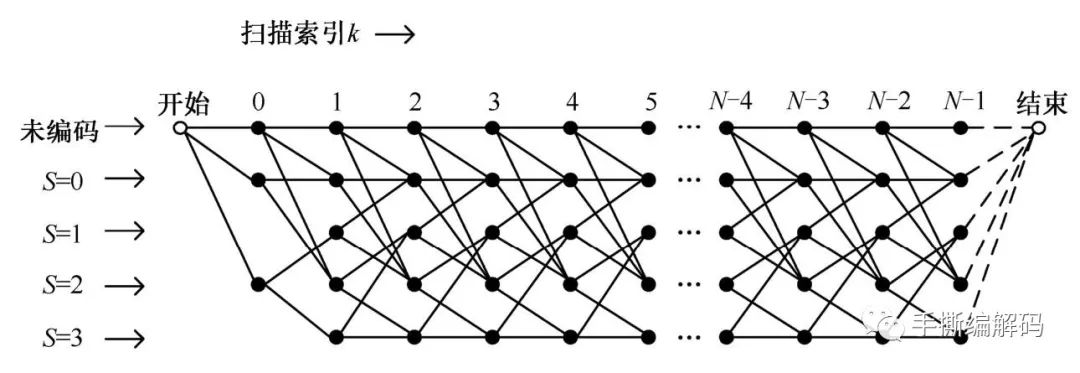
可以看到,除了状态0,1,2和3之外,网格里还包括了一个未编码状态,它用来表示按照编码顺序在第一个非零量化索引前等于0的量化索引。开始状态的率失真代价等于0,扫描索引k递增的顺序即为编码顺序,这里的N为当前块内变换系数的个数。
上面这个网格图怎么来的呢,其实就是根据下面的状态转移规则得到的。每个圆圈状态它的箭头指出总是2条。
编码器的依赖量化主要方法和步骤如下:
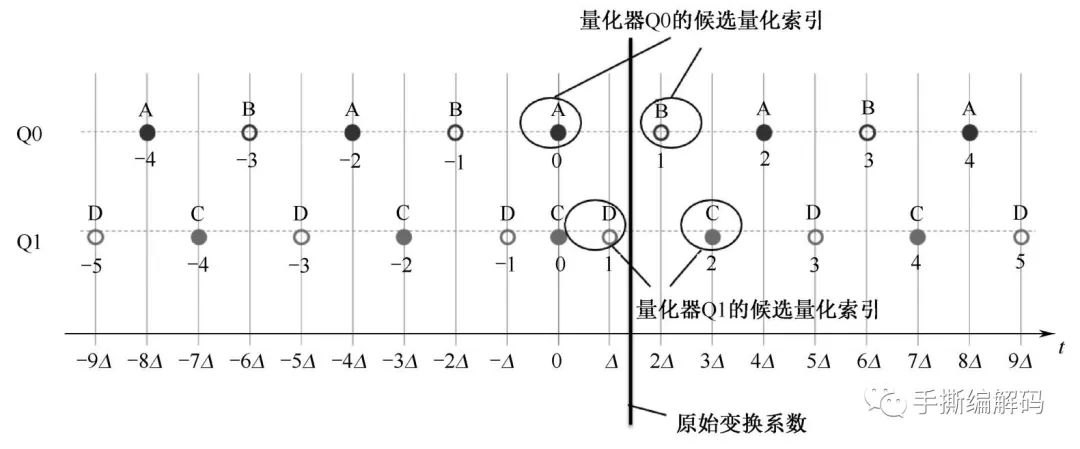
(1)首先确定当前系数的4个候选量化索引。其中每个标量量化器(Q0或Q1)会有2个最小化原始值与重建值差绝对值的候选值。候选值的确定如下图所示。
(2)当量化索引扫描从k-1转到k时,编码器要为阶段k-1的网格节点和阶段k的网格节点之间的所有连接计算出它们的率失真代价。
(3)从上面的网格结构图中可以看出,对状态0,1,2和状态3,阶段k的每个网格节点都和阶段k-1的2个网格节点相连。在计算完阶段k网格节点所有连接的率失真代价后,对于阶段k的每个节点,往往只要保留具有最小率失真代价的连接就行了,以去除那些不会被选中的分支。
(4)重复以上的过程,直到k值取到N-1结束。
此时可获得5条最终路径(5状态),从中选择率失真代价最小的那条路径。此时该路径上的量化索引序列值q0,q1,…,qN-1,这就是最终的量化索引值。
03 小结
本文仅是简单介绍了编码器和解码器角度下的DQ技术,如果要想全部弄清楚依赖量化的技术原理,我觉得还是不容易的。加上目前网上关于H.266里DQ技术相关的资料比较少,可能得从矢量量化和网格编码量化去看。
前面的Trellis Coded Quantization,TCQ不是新技术,早在1990年学术上就在研究了。它可以看成是限制了矢量分量的高维矢量量化,同时使用标量量化和网格。
可以认为网格编码量化TCQ是介于标量量化和矢量量化之间的一种量化方法,期望可以既能像标量量化那样实现简单,又能像矢量量化那样有较好的性能。网格编码量化方法建立在字符受限的率失真理论和网格编码调制理论的基础上,它使用结构化的码书和扩展的量化阶集合对信号进行量化,能够达到近乎矢量量化的性能。
参考文献
H. Schwarz, T. Nguyen, D. Marpe and T. Wiegand, “Hybrid Video Coding with Trellis-Coded Quantization,” 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 2019, pp. 182-191, doi: 10.1109/DCC.2019.00026.
作者: 手撕编解码
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。