
背景介绍
随着直播和短视频平台的蓬勃发展,如今抖音日活跃用户已超过6亿,每天都有海量的UGC视频通过不同的渠道方式如手机端(iOS/android)、网页端、PC端等上传到服务端,视频服务中台需要对每个视频做不同档位的转码和增强处理等服务,转码完成后系统会根据用户的观看环境分发不同档位和分辨率的视频。
面对内容多样化的大规模视频带来的挑战,如何更好的把控端到端视频画质的体验优化对于整个视频链路的维护和优化变得尤为关键。同时,直播视频的质量,也需要有相应的监控服务,保障直播视频质量。此外,质量数据作为一个重要的指标来衡量我们视频服务的好坏。由此,我们建设了多媒体质量评价系统,从而更精准的获取多媒体客观/主观质量,以及和质量相关的指标和问题。
我们整个多媒体质量评价系统如下图所示,我们的视频质量评价算法主要分为两个部分:Full-Reference metric 全参考评价算法,包括常用的 PSNR, SSIM, VMAF 等,主要用于评测视频转码和分发期间的质量变化;No-Reference metric 无参考评价算法,包含视频清晰度算法VQScore,美学算法 aesmod,细指标归因算法如噪声,色彩,块效应等,片源检测,实时直播监测。无参考算法主要用于分析用户上传视频的质量和更加灵活地以探针的方式接入视频处理链路的任意节点。
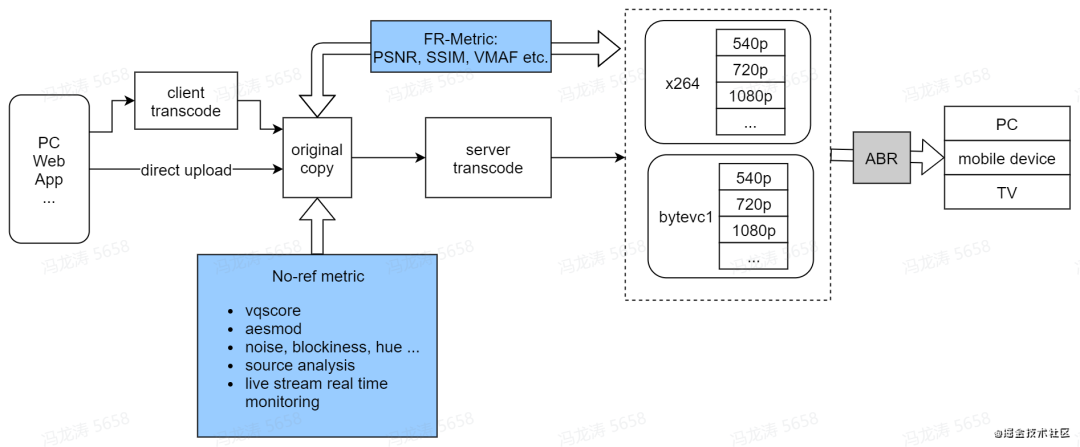
视频清晰度算法 VQScore
VQScore(Video Quality Score)是一个无参考视频质量评价指标。无参考质量评价指的是当不借助或者没有参考视频的时候,独立地进行质量评价,由机器去模仿人类对于视频的视觉感受。因为视频最终的消费者是用户,所以如果能够准确地获得用户对视频的视觉感受,就可以开展非常多的应用:视频质量监控、基于视频质量的推荐,基于人类主观感受的处理算法优化、低质视频筛查等。
由于模仿人类主观感受是一件非常困难的事,受到很多因素的干扰,工业界目前并没有很好的解决方案。基于此,VQScore 用于解决这一现状,解决公司业务中的长期痛点。
下图是整个 VQScore 系统的流程图,多媒体文件输入到系统后,首先根据相应类型文件的特性和后续对应算法的需求,进行相应策略的解码,使用不同的抽帧方式、场景切换检测等。然后通过不同的多媒体质量算法计算,得到不同维度上的质量指标。最后,进入决策环节,根据业务的需求、不同的融合策略得到最终的质量分数,和不同维度的质量指标。通过质量分数和质量指标,可以衡量多媒体的质量以及指示具体存在的质量问题。
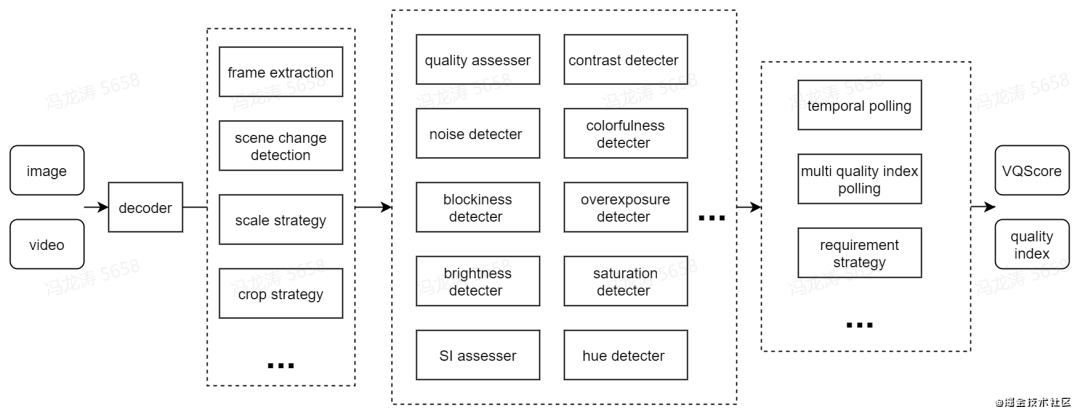
解码策略
通常进入系统的多媒体文件是经过压缩的,后续质量算法需要原始的像素信息,因此需要先经过解压缩(解码)。由于后续算法依赖解码后的结果,因此在这个过程中有许多需要注意的点,其中典型的有:
- 针对视频文件,时域上通常是冗余的,相邻帧之间的内容相似,因此为节省冗余的计算,需要对视频进行抽帧,根据业务和视频的特性,抽帧策略可以采取均匀抽帧,根据空间复杂度的抽帧,间隔连续抽帧等方式。
- 在一些视频中,会存在场景切换的情况,场景切换的方式多种多样,有淡入淡出,闪白,翻转等。通常对于正处在场景切换的帧,帧的内容通常是无意义的,对于质量算法来说是一个干扰,因此需要在抽帧过程中识别场景切换帧,然后去掉场景切换帧。
- 对于超高分辨率的视频和图片,如果在计算资源和有时间复杂度要求的情况下,需要适当地牺牲一部分分辨率信息和质量,对原始视频和图片降采样。
多媒体质量算法
多媒体质量算法是整个系统的核心,由于衡量多媒体质量是一个非常复杂和主观的问题,尤其是使用计算机去预测用户的感知质量,我们的多媒体质量算法是由许多维度的质量算法所组成,从各种角度去衡量视频质量,同时也能获得更详细的视频质量状况,从而去做不同的应用。下面简要介绍系统中正在使用的一些算法:
- 主观质量预测算法:
我们借鉴了目前学术界主流的无参考质量评价算法,使用深度学习的方式来预测视频的主观质量。对于深度学习,首要需要一个数据集去训练神经网络,我们按照目前主流的视频主观质量标注方式,让不同的用户去标注视频的主观质量,也就是Mean opinion score (MOS),视频数据来自于我们目标的业务。
由于视频主观质量是一个较为主观的指标,每个用户在标注过程中会产生波动的情况。由此,增加每个视频的用户标注数是一个可以降低波动,提高最终结果真实性的方法。在获得业务相关的可靠的数据集后,可以根据时间复杂度和神经网络的性能选择模型,在大部分场景下,我们采用常见的ResNet50的骨干网络提取图像视频的深度特征,然后回归得到预测的主观质量分数。在经过充分训练之后,稳定收敛的算法模型能够达到甚至超过与用户主观标注效果一致的主观质量预测精度。
虽然我们的算法在自建数据集上能够获取优秀的相关性指标和较低的泛化误差,但性能的上限依然取决于主观标注数据集,数据集场景覆盖不全面和带噪声的主观标注都会导致算法在实际业务中的局限性,所以在优化算法的同时我们也需要不断在多个层面迭代扩充主观标注数据集;另外深度学习算法的黑箱特性导致预测结果的解释性较差,无法对视频质量变化给出合理的归因解释,为了提升对业务问题的快速准确地定位和解决能力,还需要其他维度的多方位指标一同融合。 - 噪声检测算法:
由于视频来源多种多样,有很多由非专业用户拍摄和制作的视频,拍摄设备性能较差,拍摄场景光线环境等条件不好,导致视频中会有噪声的引入,这样的视频质量问题会给用户带来较差的主观体验,同时视频增加了一些无效且有害的信息,会增加视频的码率。对于这样一个常见的问题,我们设计了算法去检测和衡量视频中的噪声强度,噪声与正常内容在空间和时间上有着不一样的特点,由此我们提取了视频在空间上的特征如 sobel、GLCM 等,和在时间上的特征,如光流的强度和方向性等,借助了深度学习的方法,来使用这些特征去回归视频的噪声强度,最终能够较为准确地预测视频的噪声强度,从而可以提供给质量服务和去噪服务等。 - 块效应检测算法:
由于上传的视频有许多种压缩参数,编码器等,有些视频还存在多次转码的情况。过度的压缩会导致视频产生块效应的失真,导致用户主观质量的恶化,同样也增加了视频的码率。由此,我们设计了相应的块效应检测算法去检测和衡量视频中的块效应强度。块效应在空间上有非常规律的分布,因此我们分析空间上块边界的分布情况,同时利用傅里叶变换,将空域转换到频域上,能够更明显地发现规律,从而能够反应块效应的强度。 - 对比度检测算法:
视频的对比度是视频质量的一个重要环节,通常情况下,较差对比度的视频质量也会相应的较差。因此,我们设计了视频的对比度检测算法,利用了视频灰度分量分布的熵来表示视频对应的对比度,获得了与用户主观相符合的检测结果。
决策环节
得到了各个维度的质量指标,如何得到最终需要的视频质量需要最终的决策环节。首先需要根据业务的需求和输入多媒体文件的特性去决定后续决策的策略:
- 时域融合策略:
对于视频不同帧的质量,需要去做融合,其中的方法有时域平均、磁滞融合等,同时这个过程可以融合到上述算法中,端到端的调优。这个过程有时候也需要考虑业务的需求,例如对质量较差的帧需要增加权重,来更好的检测问题。 - 多种质量指标融合策略:
对于视频的不同维度的质量指标,也需要去做融合,具体的策略通常需要根据业务需求和视频种类相关,例如需要针对噪声较强的视频做筛选,需要增加噪声检测在质量分数中的权重。
应用场景
VQScore 清晰度算法,目标是能够准确地获取多媒体的质量相关的所有信息,而质量对于有视频业务的公司至关重要。我们算法的应用场景也非常广泛:
- 多媒体质量监控:点播、直播相关质量实时/离线监控,了解每个视频链路节点上的视频质量,可以及时地报警,精准地定位视频具体的质量问题。
- 低质筛选/打压:可以在成千上万的视频中筛选出低质视频,省去人工的成本,可以对低质视频做后续的增强或推荐打压等。
- 视频质量优化:能够获取到视频相关的质量指标,定位视频质量的问题,确定优化策略,从而精准地提高视频质量,节省计算资源,防止增强算法的过度恶化。
- 片源质测:对于用户上传的视频,进行质检,及时地反馈给用户,从而改善上传端原始视频质量。
美学质量算法简介
美学质量客观评估算法主要研究大众对不同图片的美学感受体验,虽然每个人由于个体的经历背景有不同的审美,但在高度信息化的社会当下,大众的平均审美对于美丑是有着比较一致的认知的,通过客观的美学质量评价算法,能够通过自动化的方式量化图像的美学因素,对于辅助用户拍照,视频封面抽取,用户推荐等不同应用场景均有明显的提升作用。
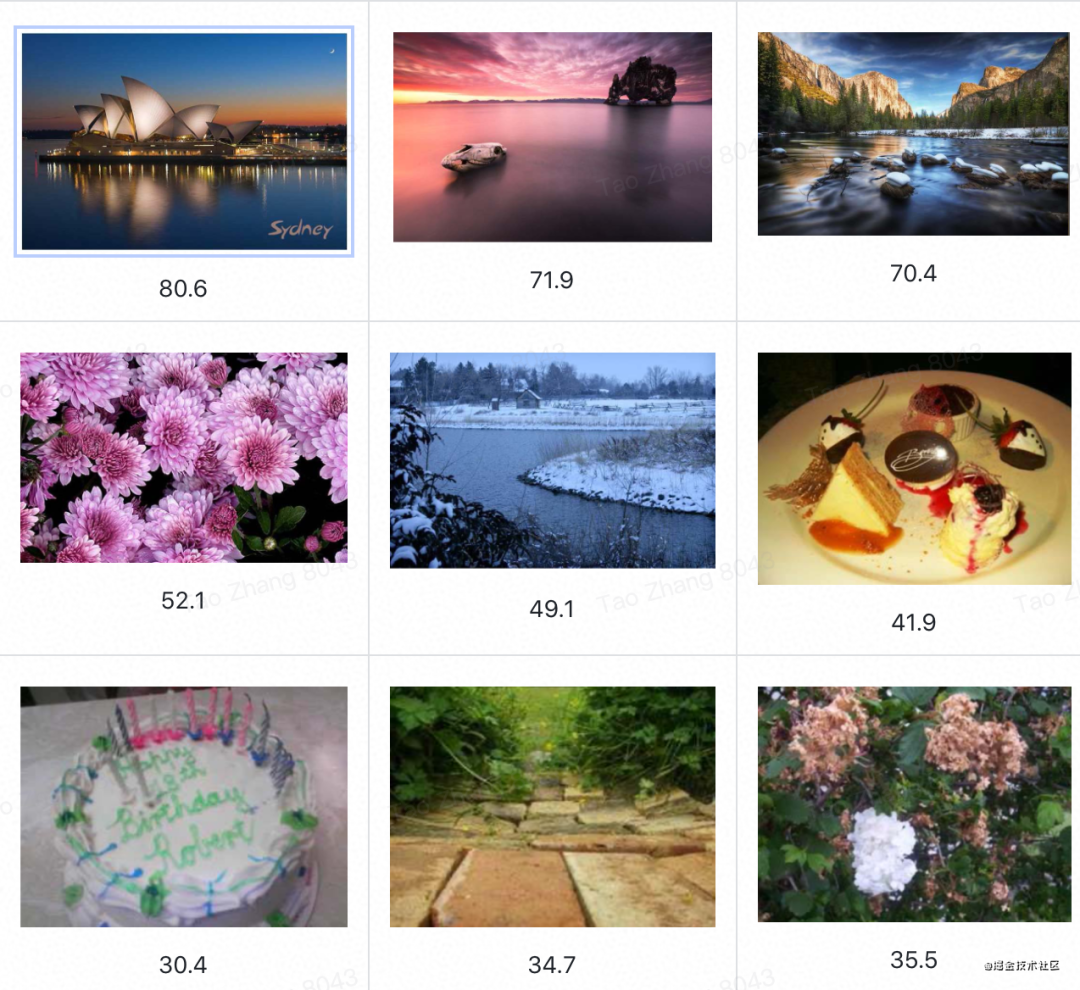 最早的美学质量评估研究是美国宾州州立大学的 James Wang 的相关工作,主要借鉴了摄影相关的一些如三分线等经验知识,通过提取亮度色彩饱和度色调、三分线构图、纹理和景深等一些基础指标来评价图片的美感度,但实际上的预测精度与主观感受仍然相差较大。随着主观标注的数据集的规模增长和深度学习的兴起,基于深度学习的美学评估也逐渐成为主流的方法。
最早的美学质量评估研究是美国宾州州立大学的 James Wang 的相关工作,主要借鉴了摄影相关的一些如三分线等经验知识,通过提取亮度色彩饱和度色调、三分线构图、纹理和景深等一些基础指标来评价图片的美感度,但实际上的预测精度与主观感受仍然相差较大。随着主观标注的数据集的规模增长和深度学习的兴起,基于深度学习的美学评估也逐渐成为主流的方法。
我们这里使用了目前比较常用的 Aesthetic Visual Analysis(AVA) 数据集来训练美学质量评估算法,其包含25K张从专业摄影网站 DPchallenge 获取多样化不同题材的摄影作品,每幅图片均有100~200人次的社区专业用户的 peer-review 评分,评分的高低与摄影作品的好坏以及 challenge 的主体对应均有一定的关系。
我们的深度学习算法主要是使用了常用的骨干网络 ResNet18 来提取图像的视觉特征,同时也是用 hyper-column 的结构来强化高级语义信息之外的 low-level 和 mid-level 的视觉特征,来丰富美学质量更加关注的纹理细节等信息,同时我们也加入了场景分类的辅助任务,通过多任务训练的方式获得更好的训练效果,在 AVA 数据集上达到了 80%+ 的二分类精度。我们的美学算法也可以视频抽帧处理的方式直接用来评估视频的美学程度。
总结
系统化的多媒体质量评估算法是视频端到端的用户主观体验优化提升工作中不可或缺的一个环节,文章中介绍的视频清晰度算法和美学算法已经持续服务于视频转码、直播和图片增强等不同业务场景的质量监控,画质优化和推荐打压等需求,但面对复杂多样化的实际业务场景,我们依然需要不断扩充主观标注视频量级,覆盖更全面的场景类型,优化清晰度算法的场景泛化能力和细粒度评估精度,从而更好地服务于 PGC/UGC 等不同的视频业务。
作者:Longtao | 来源:抖音多媒体评测实验室
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
