
这篇文章提出了一种用于小样本谈话人脸合成的动态人脸辐射场,使用音频信号耦合3D感知图像特征作为条件来快速泛化至新的身份。为了更好地建模嘴部动作,进一步学习了一个基于音频条件的人脸变形模块,将所有的参考图像变形至查询空间。大量实验表明该方法在有限的训练数据和迭代次数下生成自然谈话人脸的优越性。
来源:ECCV 2022
论文题目:Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis
论文作者:Shuai Shen 等人
内容整理: 林宗灏
引言

NeRF(神经辐射场)为谈话人脸合成提供了一种新的技术方案。基于 NeRF 的合成方法将音频特征映射到一个动态辐射场,绕过额外的中间表示,对人物肖像进行渲染。然而,由于直接将特定身份的 3D 几何和外观编码至辐射场中,模型的身份泛化能力较差。每个新的身份都需要大量的训练数据集来专门训练一个特定的模型,计算成本高昂,无法满足只有少量数据可用的实际应用场景。
针对上述问题,本文提出了一种音频驱动的动态人脸辐射场(DFRF)用于小样本谈话人脸合成,设计了一种参考机制来学习从少数观察帧到对应外观的谈话人脸的通用映射。具体而言,以 2D 观测值作为参考,将 3D 查询点分别投影回这些参考的 2D 图像空间,以相应的像素信息来指导后续的合成与渲染。为了更好地建模谈话人脸的面部动态,本文引入了一个可微的人脸变形模块,该模块表现为基于音频条件的 3D 点级变形场,将所有的参考图像变形至查询空间。
大量实验表明,本文提出的 DFRF 能够在训练数据和训练迭代次数较少的情况下生成逼真自然的谈话人脸视频。图 1 给出了与 NeRF 和 AD-NeRF 的可视化对比。给定仅有 15 秒的奥巴马视频片段进行 10k 次训练迭代,DFRF 快速泛化到这个特定身份并合成了照片级的谈话人脸结果。相比之下,在有限的训练迭代次数内,NeRF 和 AD-NeRF 在这种小样本情形下无法产生合理的结果。综上所述,本文的主要贡献如下:
- 提出了一个基于 3D 感知参考图像特征的动态人脸辐射场,该人脸场仅需15秒的短视频片段就可以快速泛化到新的身份。
- 为了更好地建模谈话人脸的面部动态,为每个参考图像学习了一个基于音频条件的 3D 点级人脸变形模块,并将其变形至查询空间。
- DFRF 仅使用少量的训练数据,在有限的迭代次数下就可以生成生动自然的谈话人脸视频,远远超过了相同情形下的其他基于 NeRF 的合成方法。
方法
DFRF
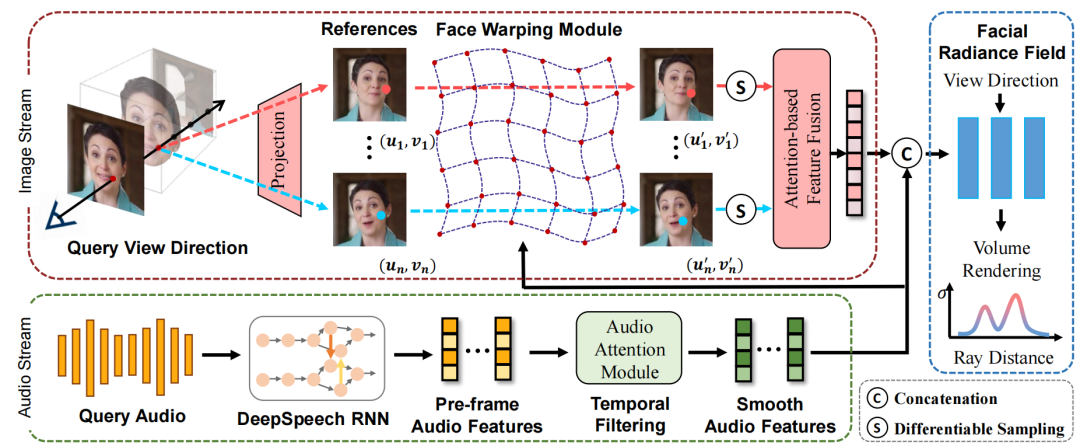
我们使用 NeRF 作为 3D 感知谈话人脸建模的主干网络。通过引入音频条件来提供变形通道。如图 2 中的音频流所示,我们首先使用预训练的基于 RNN 的 DeepSpeech 模块提取每帧的音频特征。对于帧间一致性,进一步引入时间滤波模块来计算平滑音频特征 ,其表示相邻音频特征的自注意力融合。给定 3D 查询点 p=(x,y,z) 和 2D 视图方向d= (θ,φ),音频驱动的人脸辐射场可以表示为(C,σ) = Fθ(p,d,A)。
为了实现不同身份间的泛化,我们设计了如图 2 所示的参考机制。具体来说,以 N 幅参考图像及其对应的相机位置为输入,使用两层卷积网络计算像素对齐的图像特征 F。给定一个 3D 查询点 p=(x,y,z),利用相机内参和位姿将其投影回参考图像的 2D 空间中,得到相应的2D坐标。这些来自 N 幅参考图像的像素级特征 {Fn(un,vn)} 经取整后采样,并通过基于注意力的模块融合得到最终的特征 F = Aggregation({Fn(un,vn)})。这些特征网格包含丰富的身份和外观信息,将其作为人脸辐射场的一个附加条件,使得模型可以从少数的观察帧快速泛化至新的人脸外观。双驱动的人脸辐射场表示为:
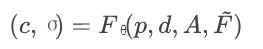
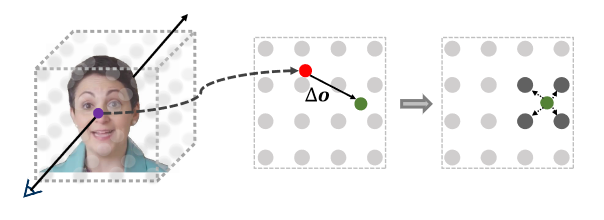
可微的人脸变形模块


体渲染

实验
消融实验
参考图像数量
我们选取了不同的参考图像数量,使用 15s 的视频片段在基准模型上进行 10k 次迭代微调。表 1 表明我们的方法对参考图像的数量具有鲁棒性。

训练数据长度
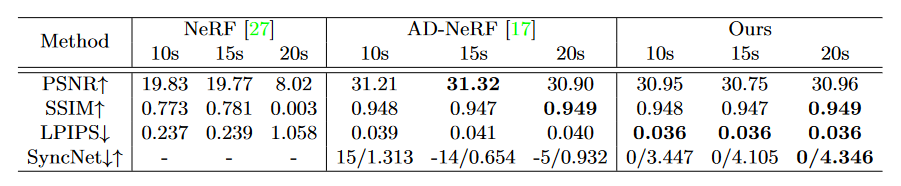
我们使用 10s、15s 和 20s 的训练视频对 NeRF 、 AD-NeRF 和 DFRF 进行 50k 次迭代微调。表 2 表明,十几秒的训练数据不足以支持NeRF的训练,AD-NeRF在视听同步方面存在缺陷,我们的方法能够从基准模型中获取更多关于通用音-唇映射的先验知识,在有限的训练数据下实现更好的视觉质量与视听同步。
可微人脸变形
表 3 给出了两个测试集上有无人脸变形模块的实验结果。所有的模型均使用 15s 视频片段微调迭代 50k 次。结果表明,该模块能够显著提高 SyncNet 置信度,视觉质量也有小幅度提升。图 4 展示了一些可视化的结果。


方法对比
小样本
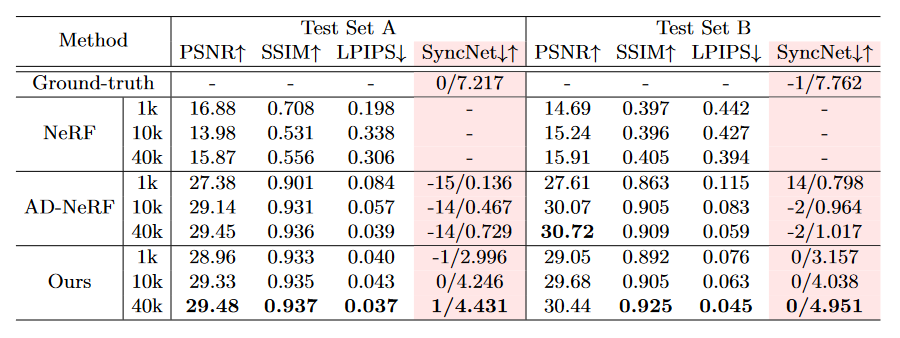
我们在两个测试集上使用 15s 的训练片段进行不同次数的迭代。表 4 的定量结果表明,我们的方法在 LPIPS 和 SyncNet 得分上远超 NeRF 和 AD-NeRF。图 5 和图 6 给出了可视化的结果对比。


大训练数据
我们使用长达 180s 的训练片段来进一步评估 DFRF 在大训练数据情形下的性能表现,并与一些高性能的基于非 NeRF 的 3D 方法进行比较。表 5 的结果表明,DFRF 在大训练数据情形下仍然优于其他方法。

跨语言
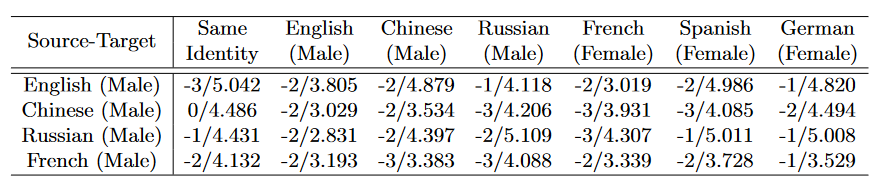
我们进一步评估了 DFRF 在不同语言和性别的音频驱动下的性能。我们选取了 4 个由不同语言片段训练的模型来对 6 种不同语言和性别的身份对象进行推理。表 6 表明,我们的方法在跨语言情形下依然能生成合理的音-唇同步。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
