
写在前面:人类对于声音的追求似乎永无止尽,从最初的无声电影,到如今具有沉浸式体验的三维声技术,每一次的技术革命都刷新了我们耳中所听到的声音的还原度和真实感。AVS3音频编解码是由数字音视频编解码技术标准工作组(AVS)与世界超高清产业联盟(UWA)联合打造的三维声编解码技术标准,也是一个具有完全自主知识产权的国产编解码标准。2022年世界杯,咪咕首次将这一标准应用在大型体育赛事直播中,本文将以这次实践案例为基础,探讨AVS3音频编解码在赛事直播应用中的关键技术与细节。
作者:韩建
审核:单华琦
来源:咪咕灯塔
原文:https://mp.weixin.qq.com/s/IdPH0r1ap6qzGGJrSMNyCA
背景介绍
回顾历史,人类对于声音的追求似乎永无止境。众所周知最开始的电影是无声的,但在1927年,情况开始有了变化,“爵士歌王”这部电影第一次在电影里播放了声音——人类实现了声音重放从无到有的技术跨越!从此电影不再仅仅是光影的艺术,而是音视频技术齐头并进的局面。但很快人们不再仅仅满足于“听的见”,人们还希望“听的逼真”,基于这样的需求,立体声诞生了,它将声音分为左右两个通道,并在左右耳之间产生微小的时间差和音量差,使得听者可以感受到来自不同方向的声音。这种技术最早在20世纪30年代被发明,后来得到了广泛应用,成为音乐会和录音室的标准配置。随着时间的推移,人们渐渐不再满足立体声的效果,多通道立体声应运而生,它将声音分为多个通道,可以更加精确地模拟真实的听觉场景。最早的多通道立体声系统是由CBS实验室发明的,被称为SQ系统,它使用了四个通道。紧随其后的是杜比环绕声,它是由杜比实验室开发的环绕声技术——使用了多个通道来创造一个360度的听觉场景。它最初被用于电影院,可以使得观众感受到来自不同方向的声音,使得电影更加沉浸式。后来,杜比实验室开发了新型三维声技术——Dolby Atmos[1],它最早于2012年推出,被广泛应用于电影院、家庭影院和游戏等场景。
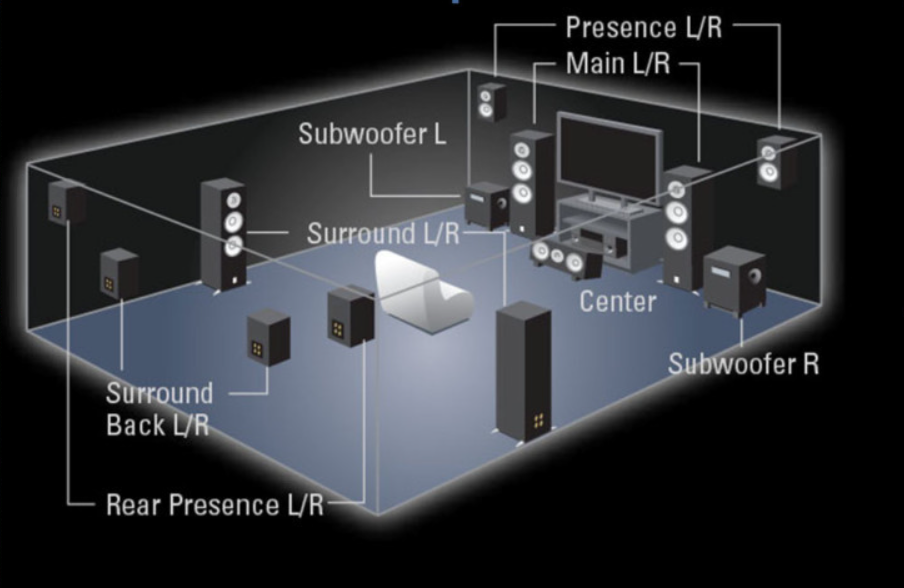
AVS3音频编解码标准
AVS3音频编解码是由数字音视频编解码技术标准工作组(AVS)与世界超高清产业联盟(UWA)联合打造的三维声编解码技术标准。AVS音频工作组主导该标准的具体技术研究以及测试验证,并发布团体标准《信息技术 智能媒体编码 第3部分:沉浸式音频》(简称为AVS3P3)。UWA音频工作组引用该标准,发布了UWA组织的团体音频标准《三维声音技术规范 第1部分:编码分发与呈现》,并将该标准所涉及的音频技术统称为菁彩声。AVS3音频编解码在行业内首次引进了神经网络编码技术,对比AVS上一代音频编解码技术,AVS3音频编解码在同等语音质量的前提下具有更高码率压缩比。另外,支持三维声编解码也是该音频标准的另外一个亮点[2]。需要说明的是,AVS3音频标准除了编解码技术外,还在标准里提供了渲染呈现技术,在2022年卡塔尔世界杯的直播实践中,咪咕采用AVS3音频编解码标准加自有渲染技术的方案来完成这次赛事直播。本文将以这次实践为基础,探讨在大型体育赛事直播中落地AVS3音频标准的技术实现。
AVS3音频的解码包括包括逆时频变换、逆频域噪声整形,逆时域噪声整形,逆频带扩展解码,上混,神经网络逆变换量化区间译码,位流服用[4],如下图所示:
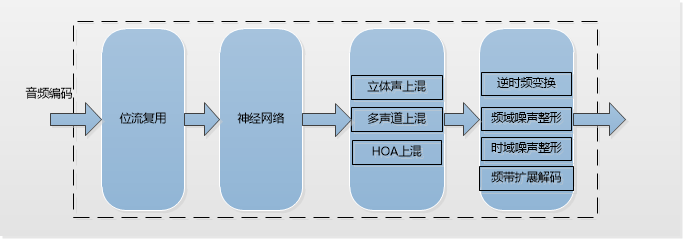
频域噪声整形

在解码端测,逆频域噪声整形则是这个过程的逆过程。
频道扩展
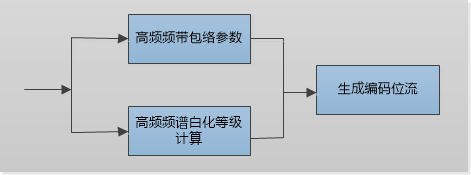
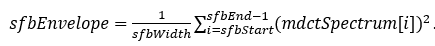
公式1 SFB计算公式
神经网络逆变换
神经网络变换模块利用神经网络对编码预处理后的MDCT系数进行变换,进一步去除频谱系数中的信息冗余,神经网络输出称为变换域系数,变换域系数用于量化和熵编码。其中神经网络模型是预先训练得到的,在编解码过程中神经网络模型参数固定不变。逆变换则是这个过程的逆过程,即对编码数据进行逆变换获得MDCT系数。
应用落地技术方案
直播系统要支持AVS3音频,系统需要从以下三个环节进行升级,如下图所示,整个直播系统包含三个环节:制作,封装传输以及解码渲染。
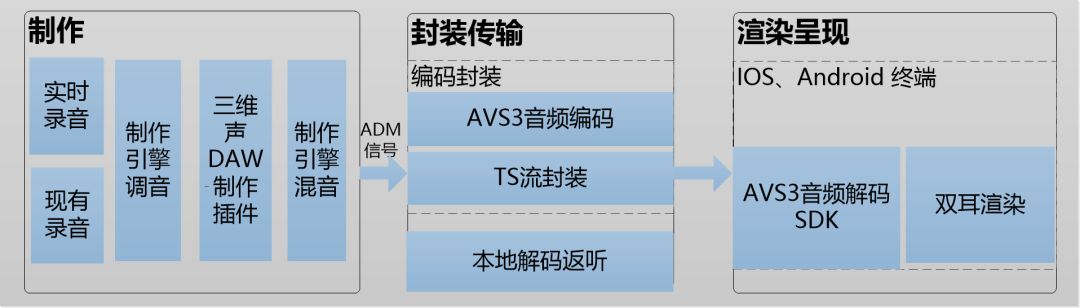
图5 AVS3音频直播系统框架图
声音制作
制作环节主要包括现场音频的录制,效果制作,元数据生成等。AVS3音频编解码支持三维声的编解码,而与传统立体声或者环绕声不同的是,三维声的音频录制需要专用的技术和设备,为了在体育赛事直播中重现三维声,需要在声音制作环节进行设备和制作技术的升级改造。
目前三维声有三种拾音方式:一种是采用双耳拾音技术(Binaural Recording)的人工头或类人工头拾音,一种是采用声场合成技术的原场(Ambisonics)传声器拾音,还有一种是通过设置能记录水平和高度信息的环绕传声器组来拾音。设备拾取的声音需要经过效果器处理,并进行元数据制作,如下图所示:
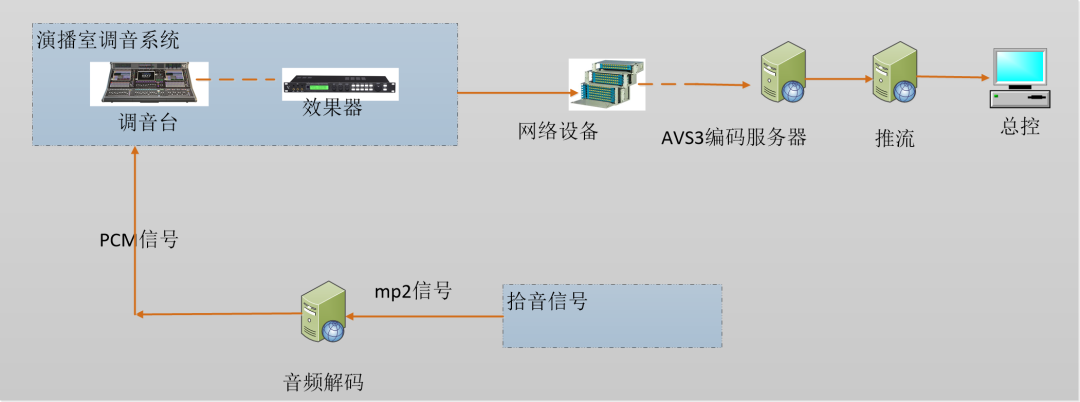
封装传输
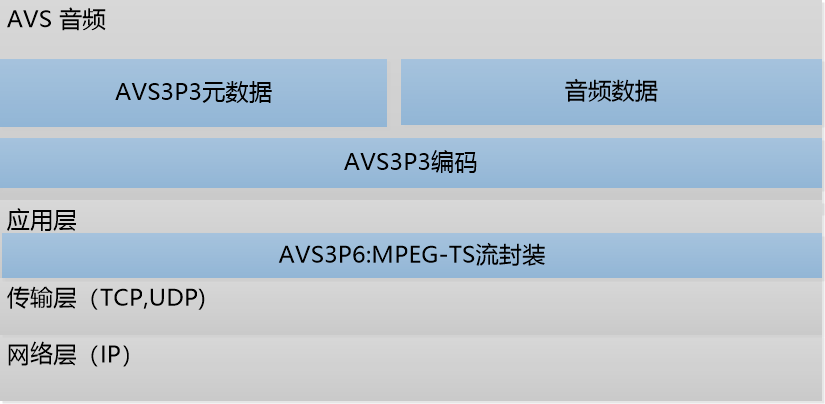
图7 AVS3音频分层封装协议示意图
使用TS作为容器来扩展对AVS3编码的支持,需要对PES分组,节目以及节目元素描述符的某些字段进行重定义[3]。对于PES分组,AVS3编码数据作为PES_packet_data_bytes携带在PES分组数据包中,并通过节目映射表中分配的stream_type字段值(0xD5)标识。与此同时,节目元素描述符注册描述符使用‘AVSA’来作为AVS3编码的标识。编码后的数据通过HLS协议进行传输,实现中需要对HLS做协议上的相应扩展,例如三维声码流的codec如下:
#EXT-X-STREAM-INF:BANDWIDTH=3464568,CODECS=”avc1.640028,av3a.02″ example.m3u8
在这里av3a.02里的02为三维声的codec ID.
解码渲染
解码渲染包括解码和渲染两个环节,工作流程如下图所示:
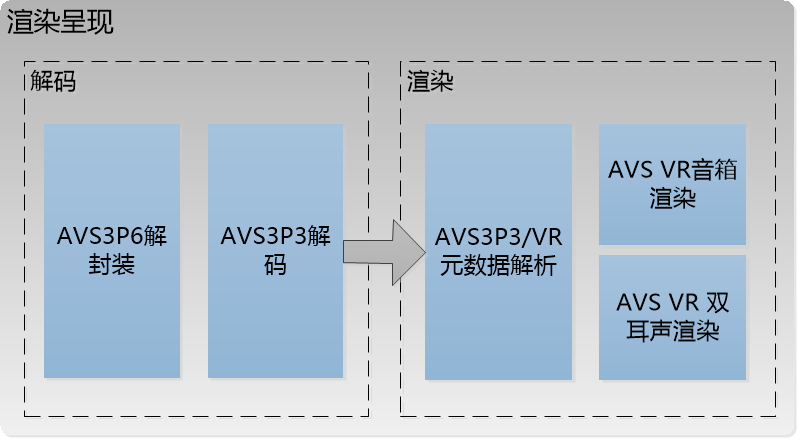
解码的输出包含两个部分:元数据部分和音频部分,为了在用户的耳机中重现赛事现场的三维声音,需要使用双耳渲染技术。顾名思义,双耳渲染的目标是通过对音频进行双耳化处理,将处理后的音频在双耳耳机里进行播放,让用户能够感受到和在真实三维环境里一样具有真实准确方位感的声音。
三维音频支持三种格式:声道格式,对象格式以及HOA格式[5]。对于声道信号,在三维音频制作时声道与扬声器一一对应进行录制,所以声道的位置信息是固定的,声道信号包含了直达声和环境混响。对于HOA格式信号,渲染播放需要进行Ambisonic解码,即在一个球面上虚拟一定数量的扬声器进行声场的重放,每个扬声器的增益可由对该扬声器位置处对应的球谐函数分量的混合叠加得到,虚拟扬声器的信号即对应的声道信号,按照声道信号的渲染流程进行渲染播放。总之,三种音频数据格式都可以通过转换,最后按照基于对象的方式来完成双耳声渲染。
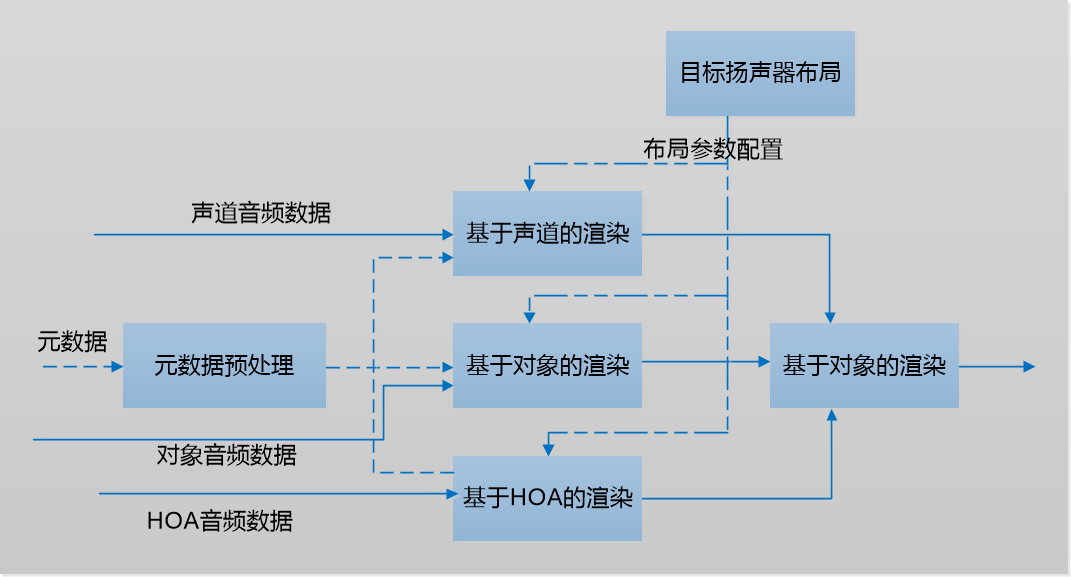
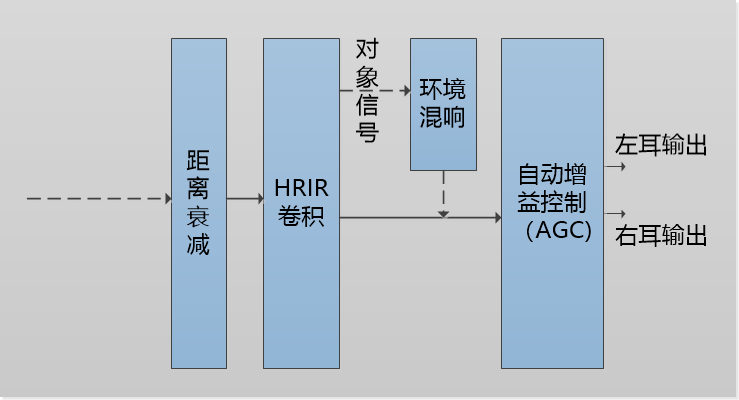
图10 双耳渲染信号处理流程图
从上述系统方案可以看出,解码以及渲染都运行在终端设备上,这对解码渲染SDK的性能提出了很高的要求,也是本次开发实践过程中所遇到的最大挑战,这里的性能既包括CPU占用率,内存的使用,也包括包体的大小优化。具体开发过程中可以根据实际情况进行有针对性的优化,本文在此不再赘述。

图11 卡塔尔世界杯直播画面
总结与展望
在现有AVS3音频技术基础上,针对上述三个问题,持续探索相关优化算法及方案,增加用户的沉浸感,提高用户对于三维声的体验满意度,将是AVS3音频技术后续演进的重要方向之一。
AVS3音频技术自从面世以来,在国内行业内得到极大的关注,除了2022年卡塔尔世界杯咪咕使用菁彩声进行直播外,央视总台和抖音集团在2023年兔年春节联欢晚会上也联手实现了使用AVS3音频技术来进行节目直播,场外观众戴上耳机就可以身临其境地感受现场震撼的三维声场,从后续反馈来看,观众对AVS3音频的体验比较正向[7]。AVS3音频的应用并不仅仅局限于直播场景,在2023年第三十届北京国际广播电影电视展览会上,央视总台首次展示了将AVS3音频技术应用在车载系统上的系统方案。此外,华为音乐与环球音乐中国联合宣布,双方将采用AVS3音频技术制作及上线品类丰富的空间音频版本内容。可以看到,AVS3音频在国内众多一线厂商以及不同领域内都开始得到应用和发展,这也从侧面证明了AVS3音频技术的商业价值和潜力。
【参考文献】
[1] https://www.sohu.com/a/279320100_100275692
[2] 三维菁彩声(Audio Vivid)技术白皮书,世界超高清产业联盟
[3] 三维声音技术规范 第1部分:编码分发与呈现,世界超高清产业联盟
[4] 信息技术 智能媒体编码 第3部分:沉浸式音频,数字音视频编解码技术标准工作组
[5] HRTF 空间插值与多通路声重放的稳定性分析 刘阳,谢菠荪 华南理工大学学报( 自然科学版) ,2013( 8) : 131-138.
[6]Spatial hearing: the psychophysics of human sound localization. Blauert J. MIT press; 1997.
[7]https://it.sohu.com/a/633825167_118778
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
