语言模型
-
Ai2 推出 Molmo 2 开源视频语言模型
Ai2(艾伦人工智能研究所)周二发布了 Molmo 2,这是一套开源视频语言模型。新增的模型以及训练数据表明了这家非营利机构对开源的持续承诺,这对希望更好地控制模型使用的企业来说是…
-
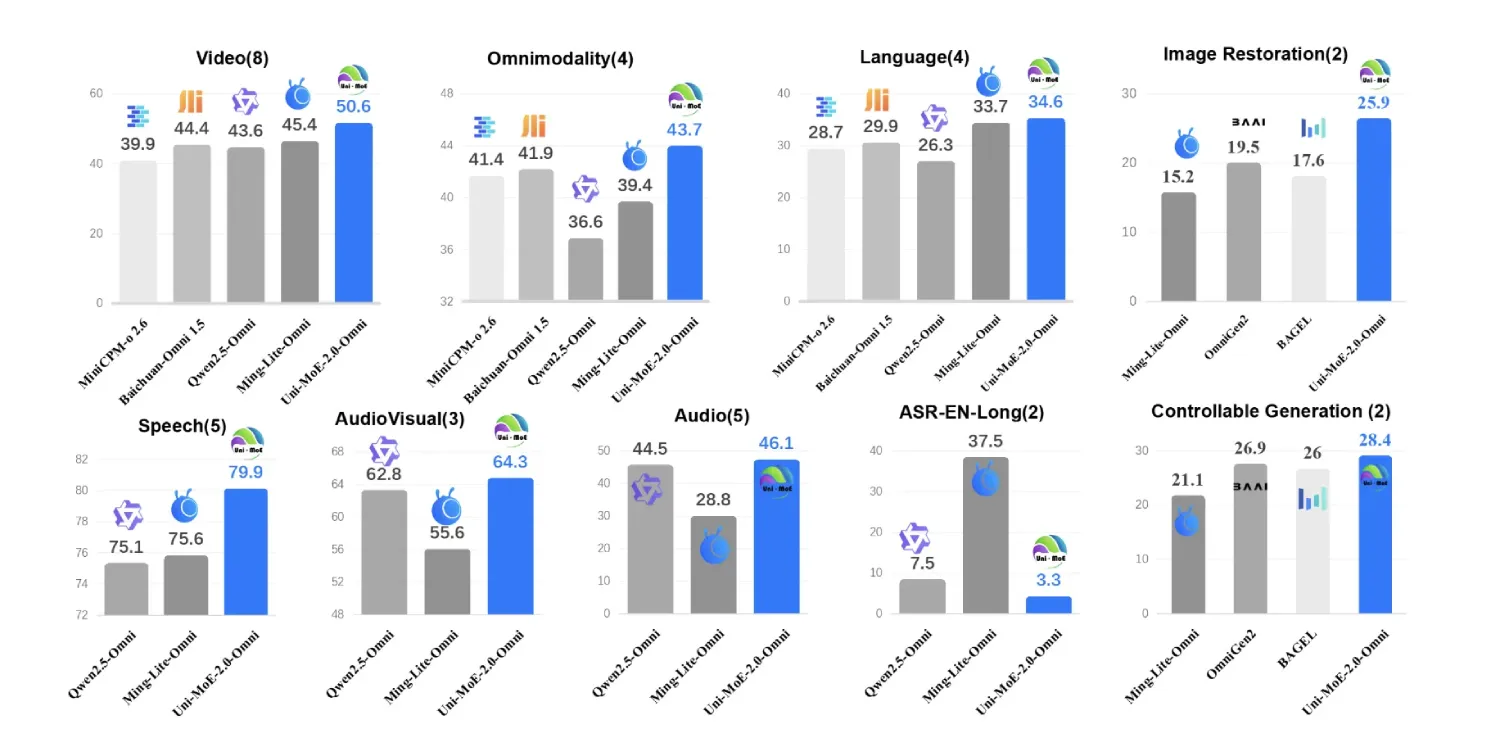
Uni-MoE-2.0-Omni:基于开源Qwen2.5-7B的文本、图像、音频与视频理解全模态MoE模型
如何构建一个能够可靠理解文本、图像、音频和视频,同时仍能高效运行的统一模型?来自哈尔滨工业大学深圳分校的研究团队推出了 Uni-MoE-2.0-Omni,这里一款全开放式全模态大型…
-
VisionWeaver:从“现象识别”到“病因诊断”,开启AI视觉幻觉研究新篇章
长久以来,我们只知道大型视觉语言模型(LVLM)会犯错,但始终缺乏一把“手术刀”,无法剖析其视觉感知的根源性缺陷。我们只知其然,不知其所以然。我们希望当 AI 模型观察图像时,不再…
-
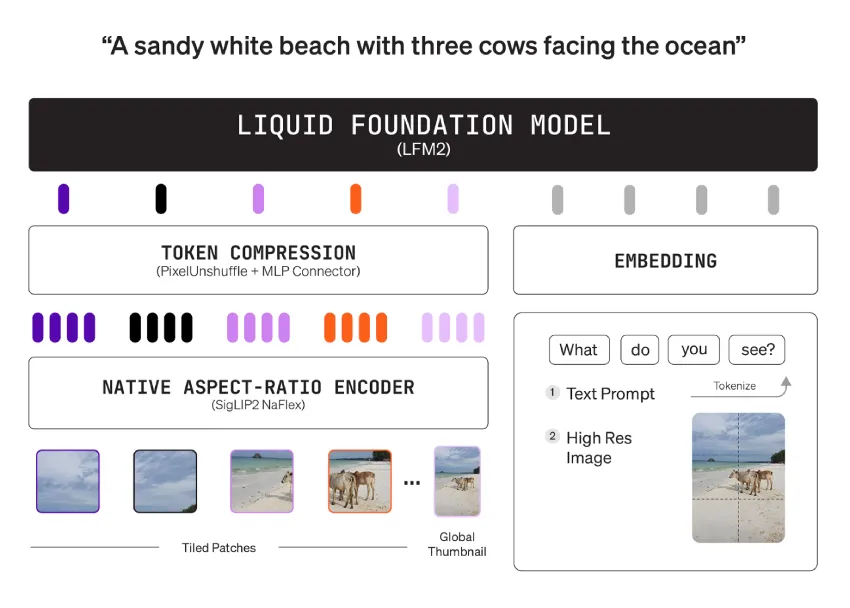
Liquid AI 发布 LFM2-VL-3B,为边缘设备带来 3B 参数的视觉语言模型
Liquid AI 发布了 LFM2-VL-3B,这是一个用于图像文本到文本任务的 3B 参数视觉语言模型。它扩展了 LFM2-VL 系列,使其超越了 450M 和 1.6B 版本…
-
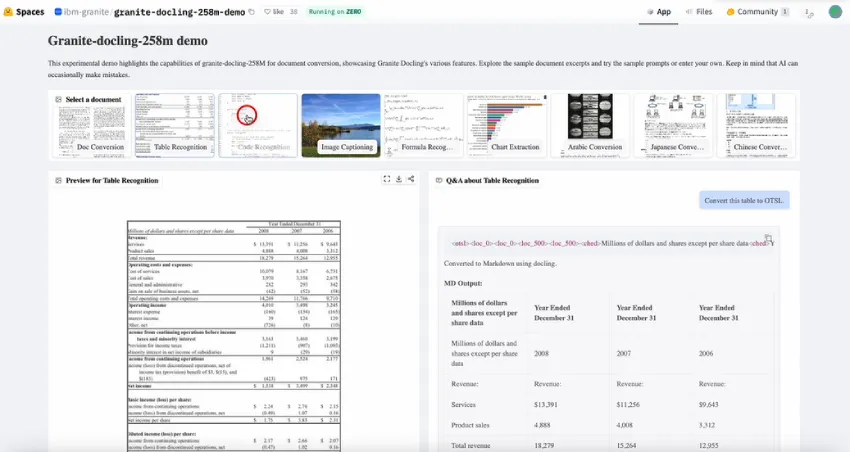
IBM AI 发布 Granite-Docling-258M:一个开源、企业级文档 AI 模型
IBM 发布了Granite-Docling-258M,这是一个专为端到端文档转换而设计的开源 (Apache-2.0) 视觉语言模型。该模型旨在忠实布局地提取表格、代码、公式、列…
-
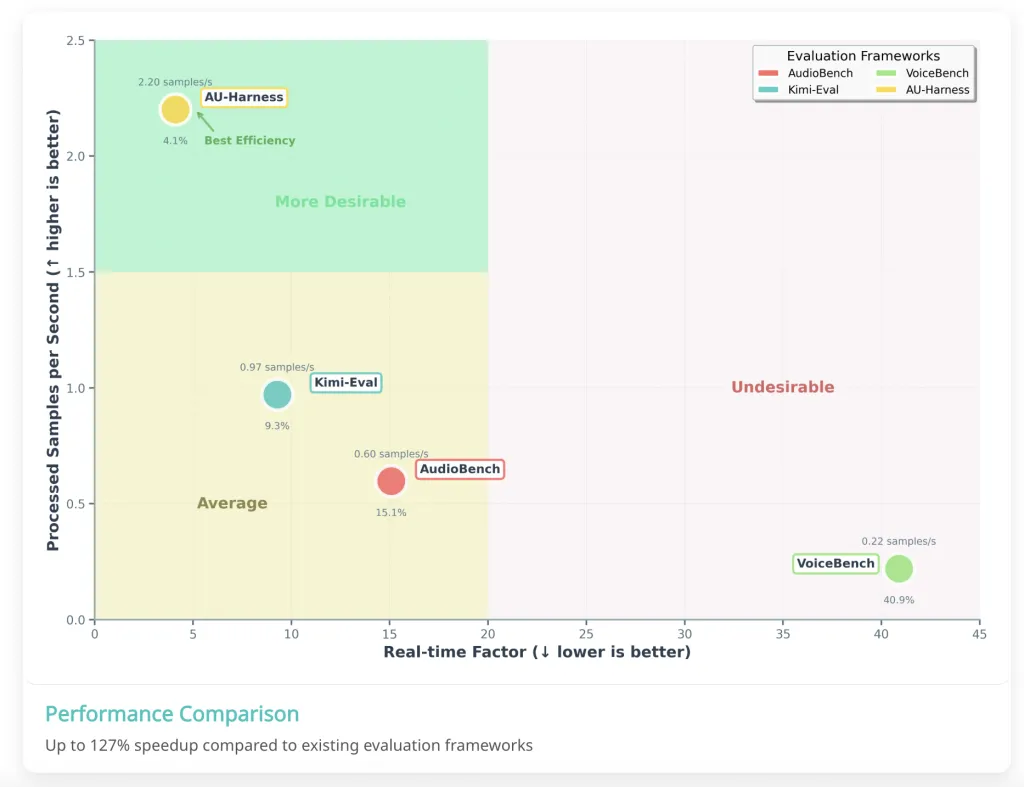
AU-Harness:用于音频 LLM 整体评估的开源工具包
语音AI正在成为多模态AI领域最重要的前沿领域之一。从智能助手到交互式代理,理解和推理音频的能力正在重塑机器与人类互动的方式。然而,尽管模型的能力迅速提升,但评估模型的工具却未能跟…
-
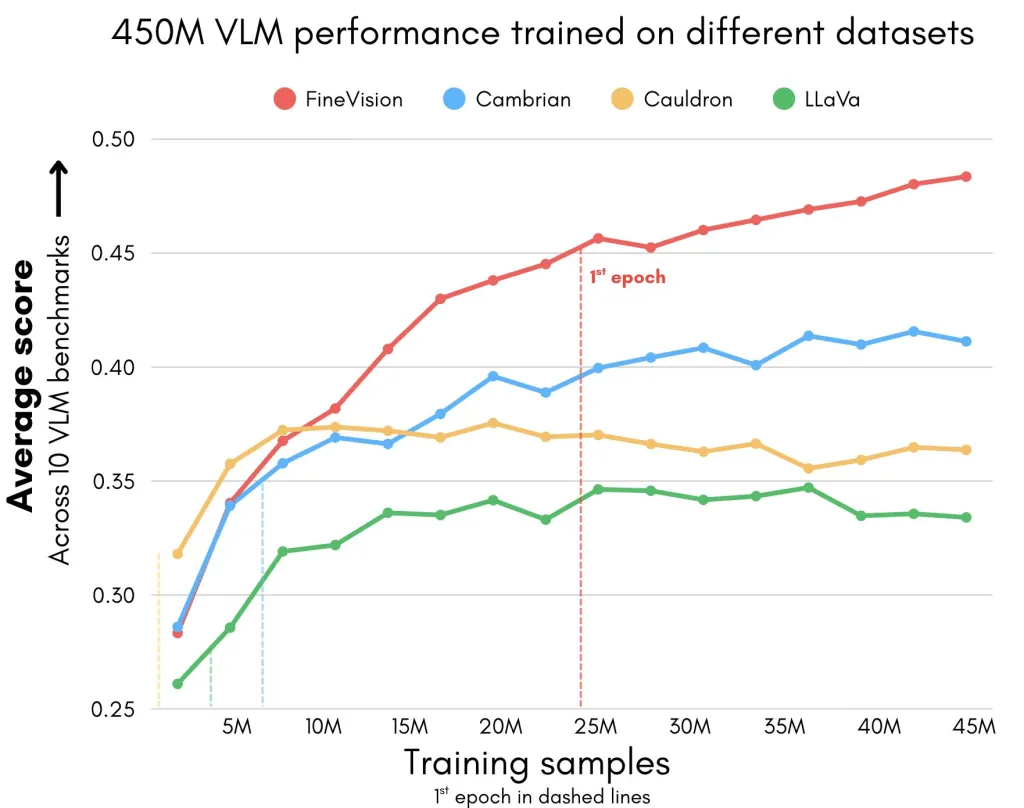
Hugging Face 开源 FineVision:一个包含 2400 万个样本的全新多模态数据集,用于训练视觉语言模型
Hugging Face 刚刚发布了FineVision,这是一个开放的多模态数据集,旨在为视觉语言模型 (VLM) 树立新标准。FineVision 拥有1730 万张图片、24…
-
Tilde AI 发布 TildeOpen LLM:一个拥有超过 300 亿个参数并支持大多数欧洲语言的开源大语言模型
拉脱维亚语言科技公司 Tilde 发布了 TildeOpen LLM ,这是一款专为欧洲语言构建的开源基础大型语言模型 (LLM) ,重点关注代表性不足且规模较小的国家和地区语言。…
-
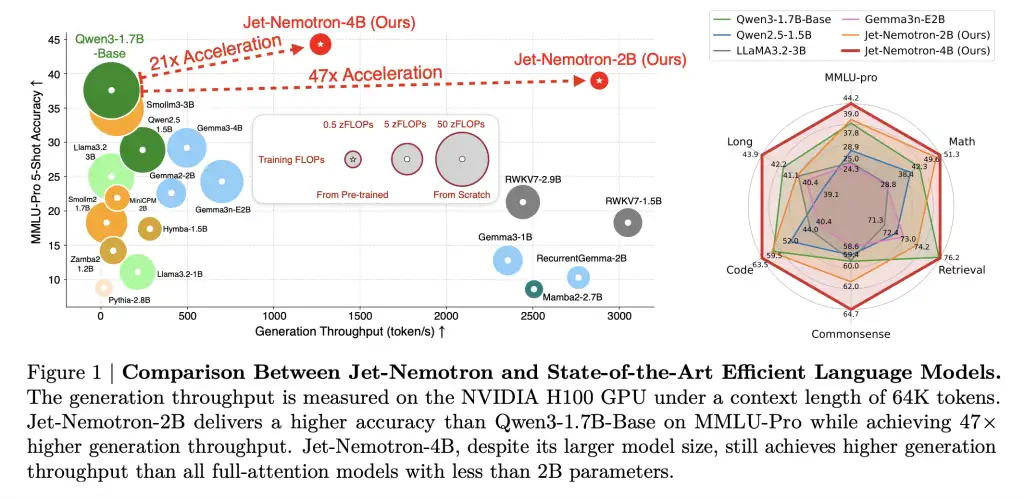
NVIDIA AI 发布 Jet-Nemotron:速度提升 53 倍的混合架构语言模型系列,可降低大规模推理成本 98%
NVIDIA 研究人员突破了大语言模型 (LLM) 推理领域长期存在的效率障碍,发布了Jet-Nemotron模型系列(2B 和 4B),其生成吞吐量比领先的全注意力机制 LLM …
-
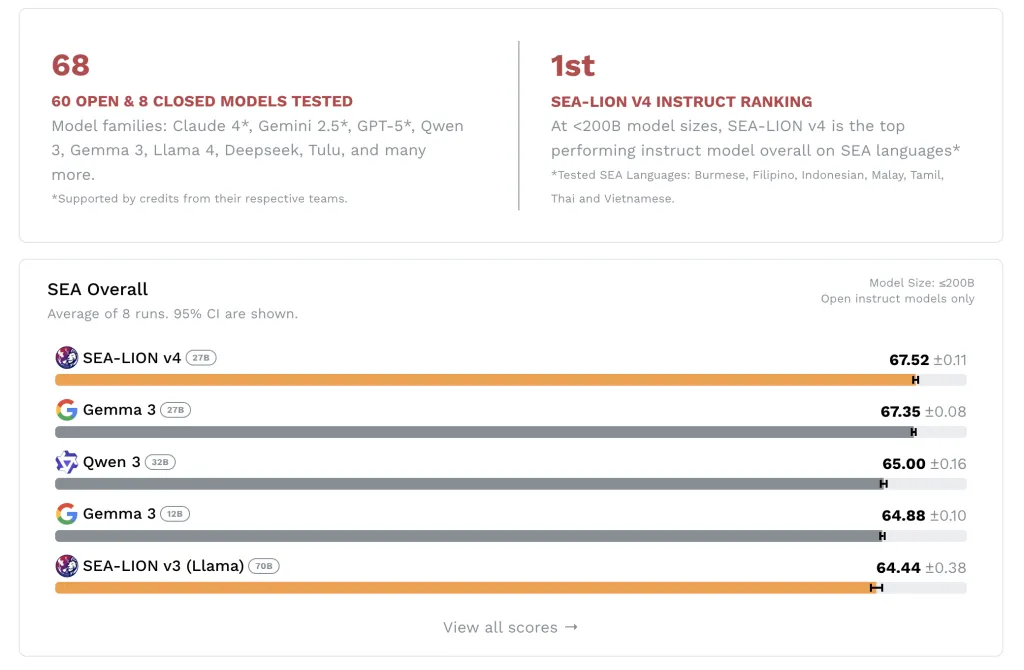
SEA-LION v4:东南亚多模态语言模型
新加坡人工智能研究院 (AISG) 发布了 SEA-LION v4,这是一个与谷歌合作开发的开源多模态语言模型,基于 Gemma 3 (27B) 架构。该模型旨在支持东南亚语言,包…
-
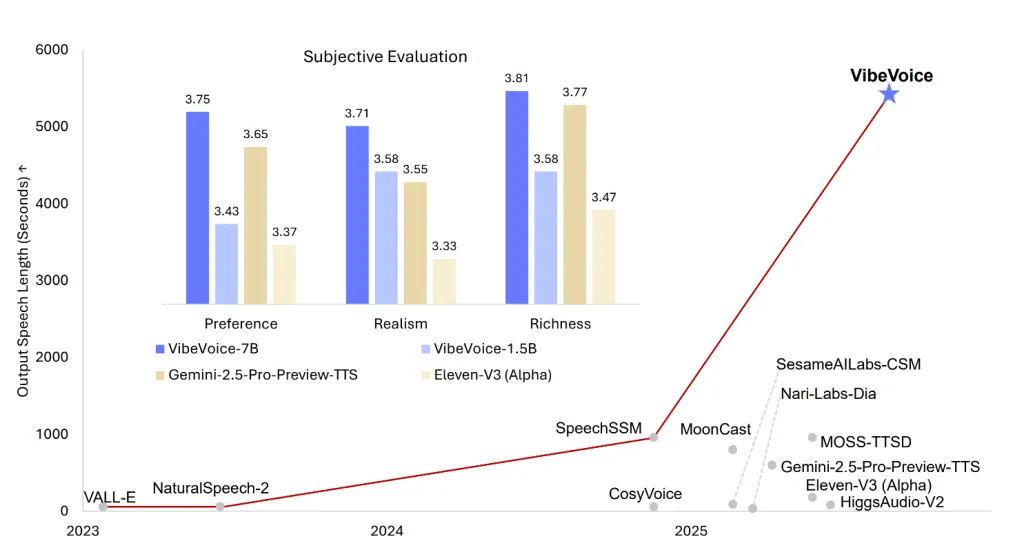
VibeVoice-1.5B:微软开源文本转语音模型,可合成四个不同说话者长达 90 分钟的语音
微软最新开源版本 VibeVoice-1.5B 重新定义了文本转语音 (TTS) 技术的边界。提供富有表现力、长篇幅、多说话人生成的音频,该音频获得麻省理工学院 (MIT) 许可,…
-
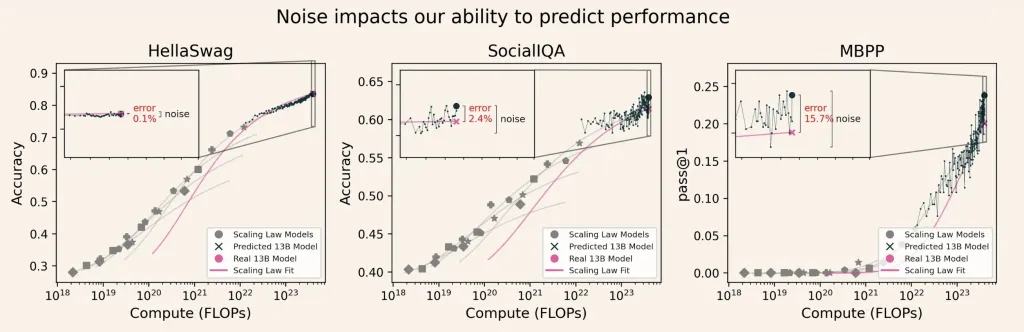
信号与噪声:解锁可靠的大语言模型 (LLM) 评估,助力更优的AI决策
评估大语言模型(LLM)的成本在科学和经济上都耗资巨大。随着该领域竞相开发更大规模的模型,评估和比较这些模型的方法变得越来越重要,不仅是为了基准分数,更是为了做出明智的开发决策。艾…
-
模型上下文协议 MCP 是 AI 基础设施中缺失的标准吗?
本文将深入探讨 MCP 的起源、技术原理、优势、局限性、实际应用以及未来发展轨迹,并借鉴行业领袖的见解和截至 2025 年中期的早期实施案例。
-
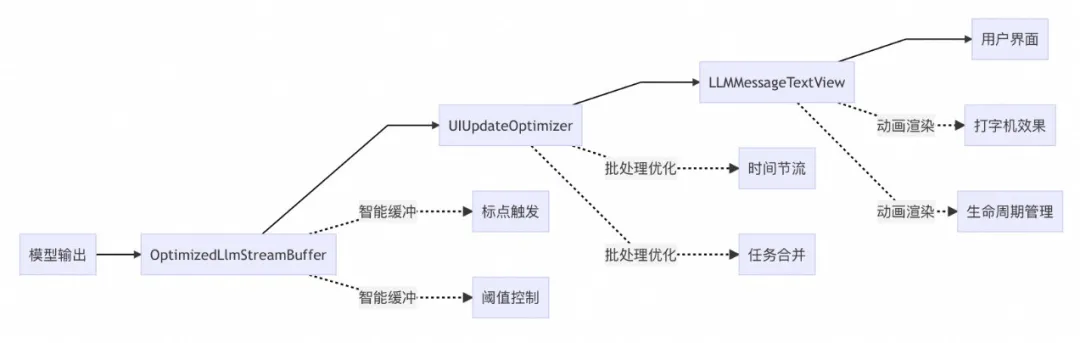
MNN LLM Chat iOS 流式输出优化实践
本文介绍了在 iOS 平台上使用 MNN 框架部署大语言模型(LLM)时,针对聊天应用中文字流式输出卡顿问题的优化实践。通过分析模型输出与 UI 更新不匹配、频繁刷新导致性能瓶颈以…
-
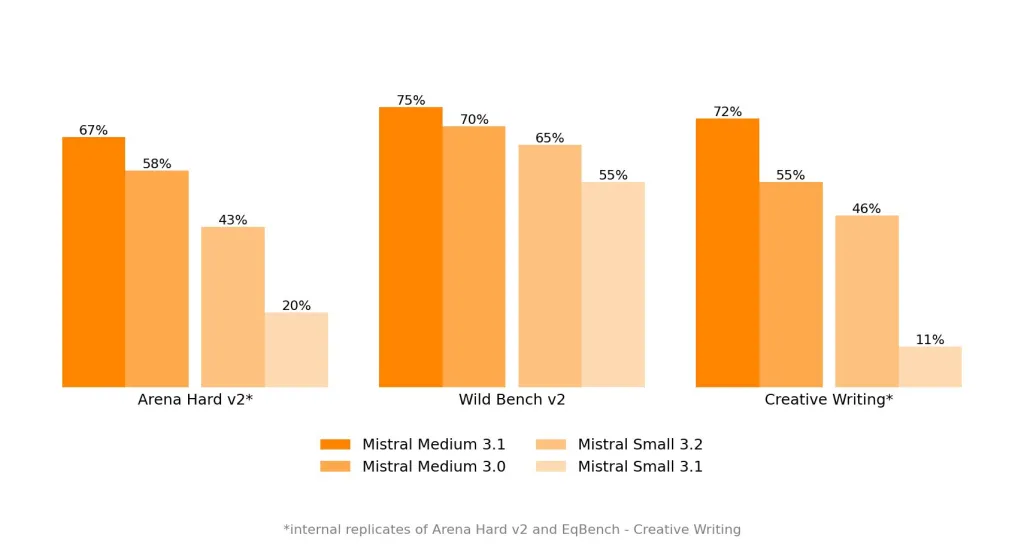
Mistral AI 推出 Mistral Medium 3.1:以卓越的性能和可用性增强 AI
Mistral AI 推出了Mistral Medium 3.1,在多模态智能、企业级应用以及大语言模型 (LLM) 的成本效益方面树立了新的标杆。凭借其快速发展的 AI 技术,M…
-
NVIDIA AI 发布 ProRLv2:通过扩展强化学习 RL 推进语言模型推理
什么是 ProRLv2? ProRLv2是 NVIDIA 延长强化学习 (ProRL) 的最新版本,专为突破大语言模型 (LLM) 的推理能力而设计。通过将强化学习 (RL) 步数…
-
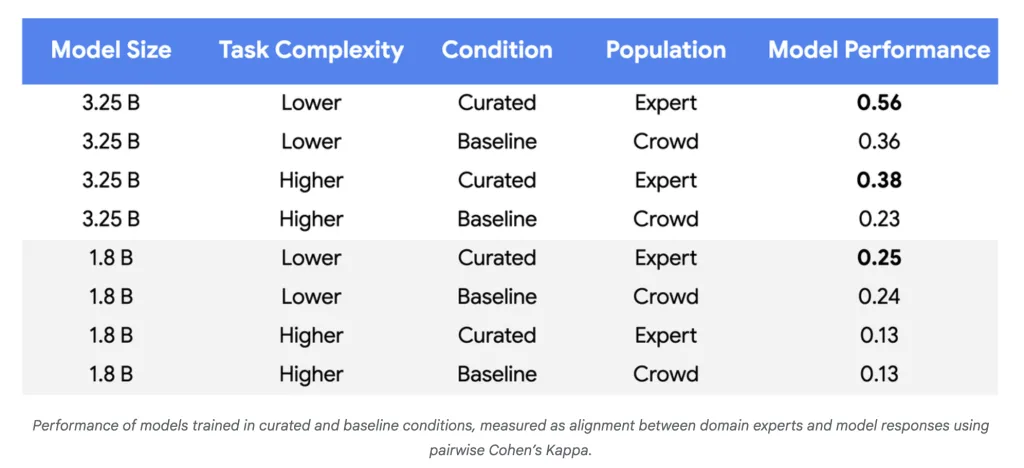
标签数量从 10 万减少到 500 以下:谷歌 AI 如何大幅缩减 LLM 训练数据
谷歌研究院公布了一种用于微调大语言模型 (LLM) 的突破性方法,该方法可将所需的训练数据量减少高达 10,000 倍,同时保持甚至提升模型质量。该方法以主动学习为核心,并将专家的…
-
LLM 中上下文工程的技术路线图:机制、基准和开放挑战
论文《大语言模型的上下文工程综述》将上下文工程确立为一门超越即时工程的正式学科,为设计、优化和管理指导大语言模型 (LLM) 的信息提供了一个统一的系统框架。 以下是其主要贡献和框…
-
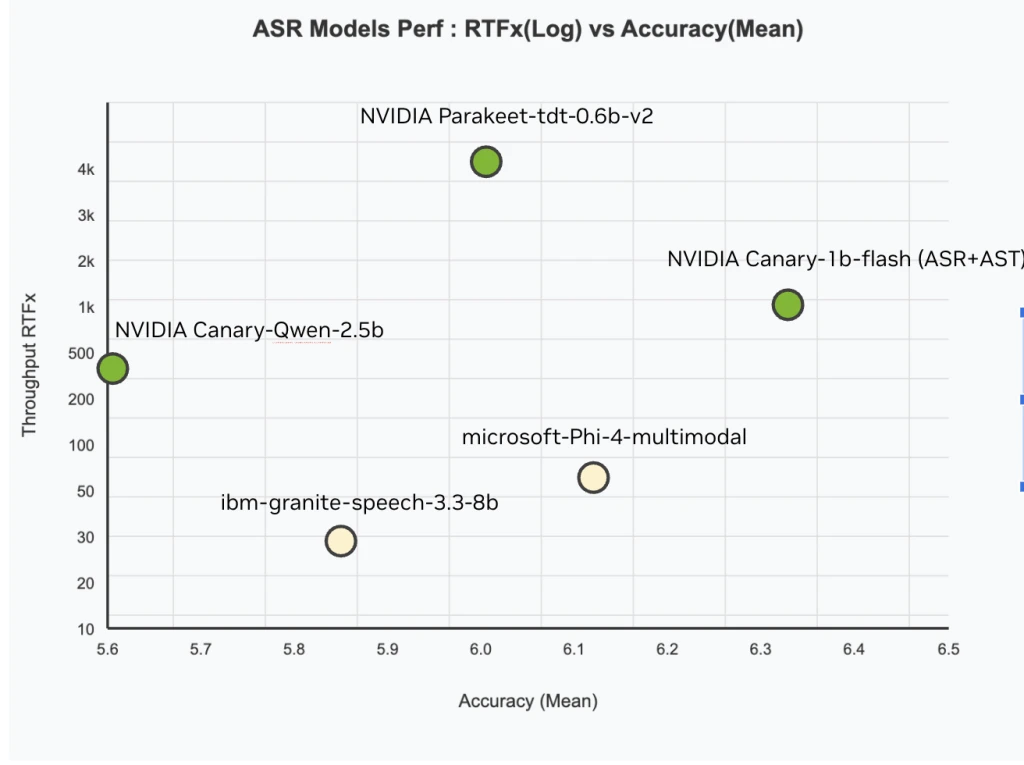
NVIDIA AI 发布 Canary-Qwen-2.5B:一款先进的 ASR-LLM 混合模型,在 OpenASR 排行榜上拥有 SoTA 性能
NVIDIA 刚刚发布了Canary-Qwen-2.5B,这是一款突破性的自动语音识别 (ASR) 和语言模型 (LLM) 混合模型,目前以创纪录的 5.63% 的词错率 (WER…
-
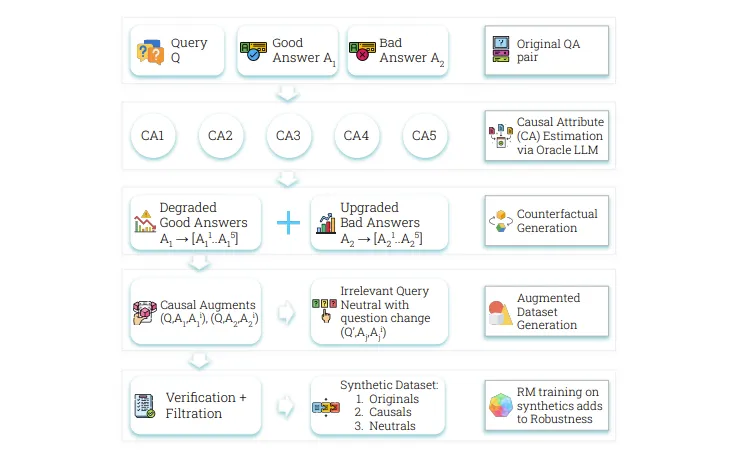
Crome:Google DeepMind 的因果框架,用于 LLM 对齐中建立稳健奖励模型
奖励模型是将 LLM 与人工反馈对齐的基础组件,但它们面临着奖励黑客攻击的挑战。这些模型关注的是诸如响应长度或格式等表面属性,而不是识别诸如真实性和相关性等真正的质量指标。这个问题…